 谷咕云计算
谷咕云计算 
腾讯云消息队列 CKafka 版
消息队列 CKafka 版(TDMQ for CKafka)是一个分布式、高吞吐量、高可扩展性的消息系统,100%兼容开源 Kafka API 0.9至2.8版本。CKafka 基于发布/订阅模式,通过消息解耦,使生产者和消费者异步交互,无需彼此等待。
消息队列 CKafka 版
分布式、高吞吐量、高可扩展性的消息服务,100%兼容开源 Apache Kafka 0.9-2.8
消息队列 CKafka 版(TDMQ for CKafka)是一个分布式、高吞吐量、高可扩展性的消息系统,100%兼容开源 Kafka API 0.9至2.8版本。CKafka 基于发布/订阅模式,通过消息解耦,使生产者和消费者异步交互,无需彼此等待。CKafka 具有高可用、数据压缩、同时支持离线和实时数据处理等优点,适用于日志压缩收集、监控数据聚合、流式数据集成等场景。
应用场景
1、消息队列 CKafka 版 结合大数据套件 EMR,构建完整的日志分析系统。首先通过部署在客户端的 agent 进行日志采集,并将数据聚合到消息队列 CKafka 版,之后通过后端的大数据套件如 Spark 等进行数据的多次计算消费,并且对原始日志进行清理,落盘存储或进行图形化展示。
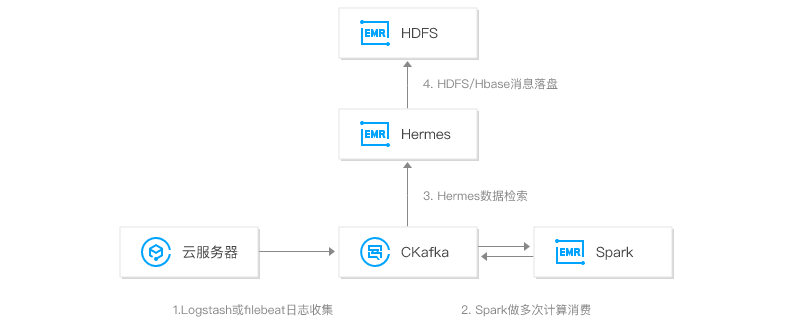
2、
消息队列 CKafka 版 结合流计算 SCS , 用于实时/离线数据处理及异常检测,满足不同场景需要:
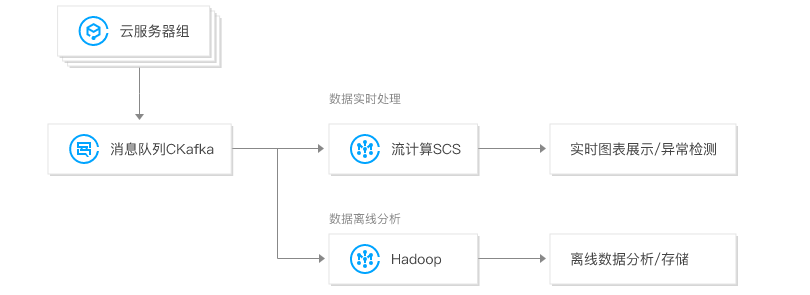
3、消息队列 CKafka 版 结合无服务器云函数 SCF , 可用于日志消费处理、微服务以及大数据分析等场景。同时支持自定义数据处理,满足不同场景下的消息转储需求。

4、
CKafka 连接器可应用在需要进行数据上报的场景。如手机 App 的操作行为分析、前端页面的 Bug 日志上报、业务数据的上报等等。一般情况下,这些上报的数据都需要转储到下游的存储分析系统里面进行处理(如 Elasticsearch,HDFS 等)。在常规操作中,我们需要搭建 Server、购买存储系统、并在中间自定义代码进行数据接收、处理、转储等。流程繁琐,长期系统维护成本高。
CKafka 连接器旨在用 SaaS 化的思路解决这个问题,目标是通过如下两步:界面配置、SDK 上报,完成整个链路的搭建,并基于 Serverless 理念,以按量计费,弹性伸缩,无需预估容量等方式,简化客户的研发投入成本和实际的使用成本。

5、
CKafka 连接器支持基于 CDC(Change Data Capture)机制订阅多款数据库的变更数据。如订阅MySQL 的 Binlog,MongoDB 的 Change Stream,PostgreSQL 的行级的数据变更(Row-level Change),SQL Server 的行级的数据变更(Row-level Change)等。例如,在实际业务使用过程当中,业务经常需要订阅 MySQL 的 Binlog 日志,获取 MySQL 的变更记录(Insert、Update、Delete、DDL、DML 等),并针对这些数据进行对应的业务逻辑处理,如查询、故障恢复、分析等。
在默认情况下,客户往往需要自定义搭建基于 CDC 的订阅组件如(Canal、Debezium、Flink CDC 等)来完成对数据库的数据订阅。而在搭建、运维这些订阅组件的过程中,人力投入成本较高,需要搭建配套的监控体系,保证订阅组件的稳定运行。
基于此种情况,CKafka 连接器提供 SaaS 化的组件,通过界面配置化的完成数据的订阅、处理、转储等整个流程。
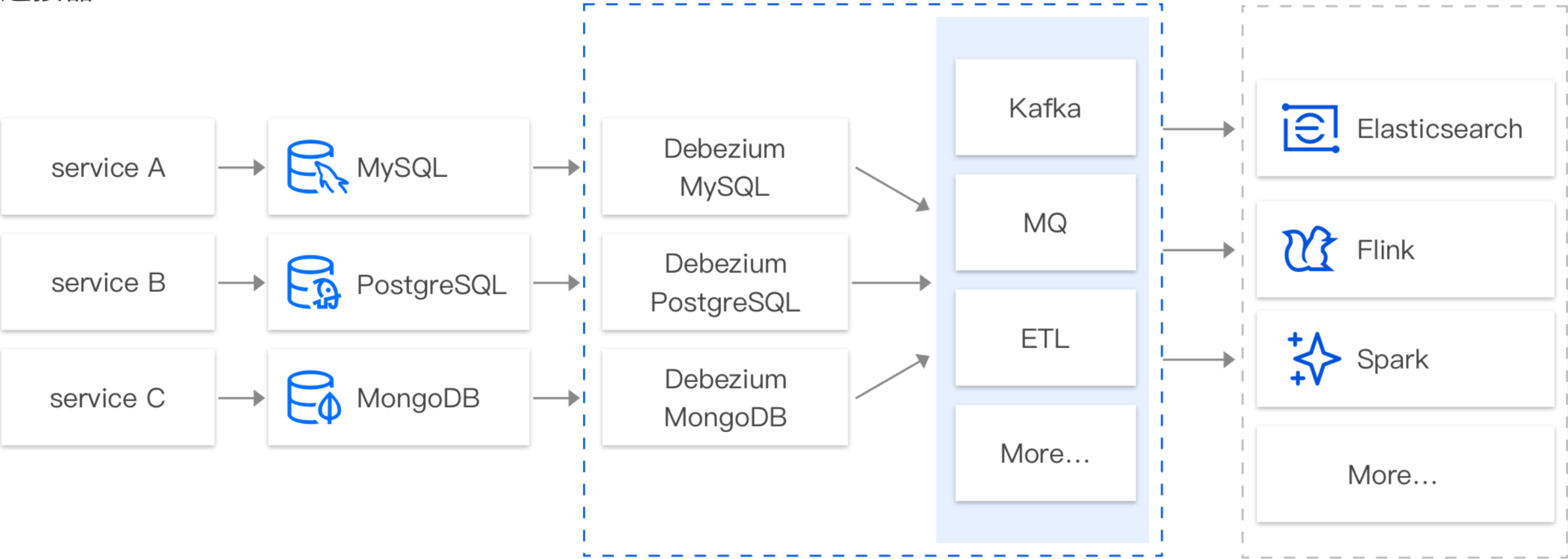
6、
CKafka 连接器支持将不同环境(腾讯公有云、用户自建 IDC、跨云、混合云等)的不同数据源(数据库、中间件、日志、应用系统等)的数据集成到公有云的消息队列服务中,以便进行数据的处理和分发。在实际业务过程中,用户经常需要将多个数据源的数据汇总到消息队列中,例如同一个应用业务客户端数据、业务 DB 的数据、业务的运行日志数据汇总到消息队列中进行分析处理。正常情况下,需要先将这些数据进行清洗格式化后,再做统一的转储、分析或处理。
CKafka 连接器提供了数据聚合、存储、处理、转储的能力。简而言之,就是提供数据集成的能力,将不同的数据源连接到下游的数据目标中。
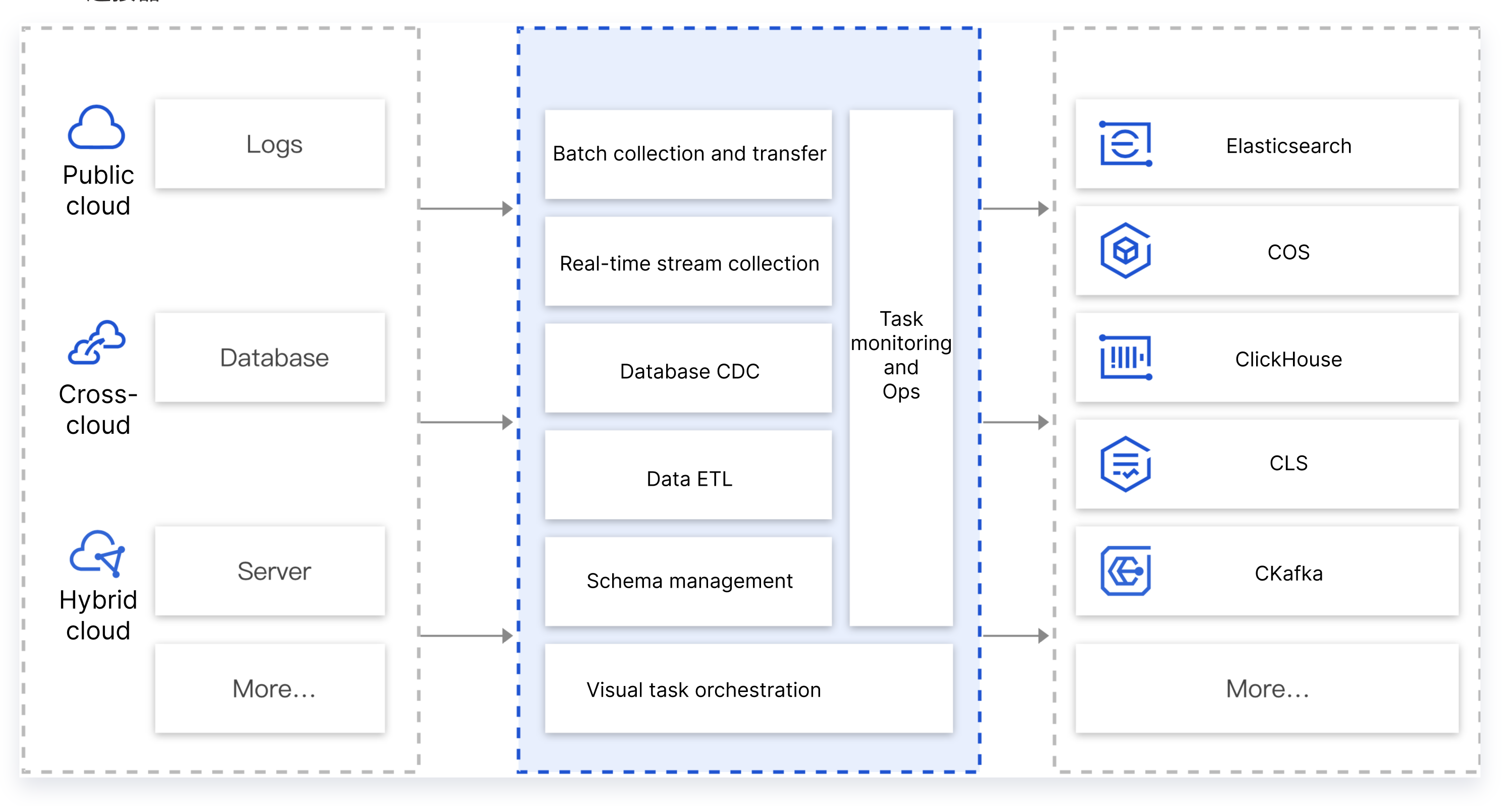
Serverless 应用中心 是业界非常受欢迎的无服务器应...
云函数(Serverless Cloud Function,...
消息队列 CMQ 版(TDMQ for CMQ,简称 TDM...
消息队列 Pulsar 版(TDMQ for Apache ...
消息队列 RabbitMQ 版(TDMQ for Rabbi...
消息队列 RocketMQ 版(TDMQ for Apach...